MCP, Explained for Real Estate
Most AI writing in real estate stops at "you need clean data" and ends with a vendor recommendation. This starts where that thinking stops.

Open LinkedIn on any weekday. Count the asset managers posting their prompt libraries. The ones who bought a Mac Mini to run AI models locally. These are smart people doing someone else's job for free. Meanwhile their actual business sits.
The tools themselves are real. Claude and ChatGPT are useful, today. You can voice chat with them. You can run them inside Excel. You can drop a stack of financials into a window and have real analysis back in under a minute. And nobody knows which workflows get fully automated next. Not me, not Anthropic or OpenAI, not the loudest voice in your feed. That uncertainty is the reason to experiment, not the reason to wait.
But the moment you try to move from "interesting personal tool" to "thing my firm runs on", the walls show up fast.
Your data is not even yours to begin with. Most of it lives in property management systems your operators control, maintained to their standards, refreshed on their schedule. Getting it out, standardizing it, and making it usable is the job before the job.
You can drag and drop ten files. A hundred, fine. Real operations are running thousands a day.
The model does not know how your firm defines same-store NOI. Or whether your tradeouts compare new leases to expiring leases or to market. Or how your asset managers split recurring CapEx from growth CapEx. It was trained on public text written by people who calculate those things differently than you, and it will hand you back a confident number grounded in a definition you would reject.
And the numbers themselves move. Backfills and post-close adjustments are normal. A chat window has no way to know which version it has - and if you want a fresh copy, you have to upload it manually again.
To solve these problems reliably, you need the software underneath. An ingestion layer that handles thousands of files a day across every property management system your operators control. A semantic layer that holds your firm's definitions, so every number you ask about uses your math, not the internet's average. A computation layer that runs your formulas deterministically, before anything reaches the model. Three layers, doing the work that does not get easier when a new model ships.
And there is a standard for how any model reaches that platform. MCP. Model Context Protocol. Think of it as a universal adapter: any model - Claude, Gemini, ChatGPT, whatever ships next quarter - can plug in, ask questions, and get structured answers back.
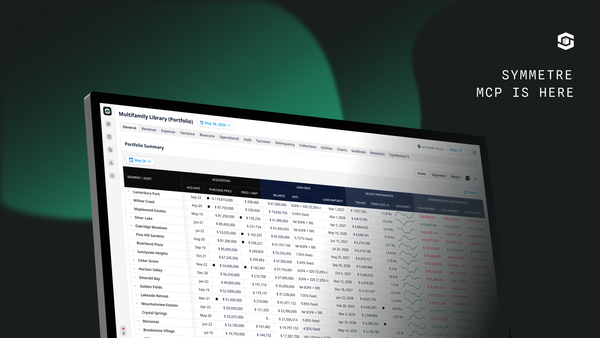
MCP is the protocol. The platform behind it is what we build at symmetRE.
What it actually looks like in practice
Here is what using MCP feels like day to day.
The data is processed and computed by symmetRE. Every number traces back to source transactions in the underlying property management systems.
You open Claude, or ChatGPT, or whatever chat interface you prefer. The portfolio is already there. You did not upload anything. You did not stitch together exports from a dozen systems. The model has access because the MCP connection handles it. What sits behind that connection is the point. It answers the problems that broke the chat window in the first place.
The volume is handled for you. The data is fresh. Move-outs booked yesterday are there this morning. Leasing activity from last night is reflected in the trend. Post-close adjustments propagate in without anyone re-uploading anything. Thousands of files a day are flowing through the layer underneath, and ten years of history are already there.
symmetRE processes data from property management systems, applies the semantic layer of lease tradeout definitions, and computes before passing to AI of your choice.
The definitions hold all the way down. Ask how an asset performed on this day five years ago and the number means the same thing now as it did then. Ask why occupancy dropped, and the answer reaches into move-out reasons, traffic, tour counts, lead-to-lease conversion, which floorplans are losing residents and which are filling. "Occupancy dropped" becomes "occupancy dropped because of X" without you specifying where to look.
The conversation does not start over. Ask about an underperforming asset today, implement a change, come back in six weeks and ask whether it worked. The data has moved on. The conversation has not. There is a record of what you asked, what the system said, and what happened next. You are not reconstructing context from memory or three different email chains.
A shared data world, consistently defined and continuously updated, that you and your team can interrogate from whatever interface you happen to be working in. Chat. Excel. PowerPoint. Same underlying answer.
Don't sit this out
Anthropic, OpenAI, and Google are going to keep shipping frontier models. That is not a prediction. That is the shape of the industry. Capability will keep advancing, interfaces will keep improving. Sit this out because the current generation does not do exactly what you want, and you will be three generations behind the people who did not.
Then the part I actually care about happens. The asset managers, analysts, and operators closest to the work start finding the use cases that matter. Which ones repeat. Which ones save time. Which ones change a decision. Some of those will be things none of us wrote down in a product brief. Some will turn out to be wrong. The good ones harden into workflows the industry can actually run on, with the audit trail and the controls the business requires.
That is the loop. Labs push capability. Vendors make it reachable. Practitioners find out what it is good for. Nobody in that chain can skip their part.
Want to see how it works on your portfolio? Book a demo.
Artur Gaifutdinov is co-founder and CTO of symmetRE, a portfolio-wide reporting and intelligence platform for real estate owners. Master's in Software Engineering from Carnegie Mellon. Previously built fraud-prevention systems feeding real-time credit decisions at Avant. Eight years in proptech, building the data and computation infrastructure that holds up at production scale, across different asset classes.